You are here
Developing joined up RDM infrastructure for institutions
A report on a session at the JISC MRD Programme workshop on achievements, challenges and recommendations, titled "Repositories, portals and institutional systems” with the general theme of how to join up institutional systems for research data management.
This is a report on Session 4A at the JISC MRD Programme workshop on achievements, challenges and recommendations. This session titled "Repositories, portals and institutional systems” was summed up by programme manager Simon Hodson as having the general theme of how to join up institutional systems. It served up five excellent examples of approaches to joining up within different institutional contexts – these examples are summarised here. Between them they have something to offer other institutions currently examining their infrastructure with a view to embedding research data management services. For further details please consult the project blogs and the presentation slides.
Simon Price, presenting on behalf of data.bris, covered four aspects of integration that were relevant to their project:
- Storage: the storage facility at Bristol, offering a 5TB of space for free, with a pay-once-store-forever (defined as 20 years) model. There are linkages to the repository via metadata, and to institutional management information systems. The storage system deals with the deposit of thousands of files, organised in directories, presented in a wide range of formats. Size of data stored varies from hundreds of megabytes to the terabyte range. The storage facility development had a focus on security and securing access, slightly different to the publication and sharing focus of the project. With an existing governance infrastructure and communication links in place, this existing facility was seen as providing a boost to data.bris, but changes were required to accommodate the data publication and sharing aspect.
- RIM: the parallel development of a CRIS (PURE), which required the project to consider different ways of integrating with PURE, as well as being mindful of the timeline of PURE progress.
- Identifiers: The project developed a system of assigning DOIs to published datasets, whilst also enhancing the data deposit interface through integration with institutional systems to retrieve depositor identifiers.
- Interface: The project came back to the use of CKAN as a basis for the viewing interface to data – their interest in assessing CKAN was re-ignited after hearing more about the Lincoln Orbital project.
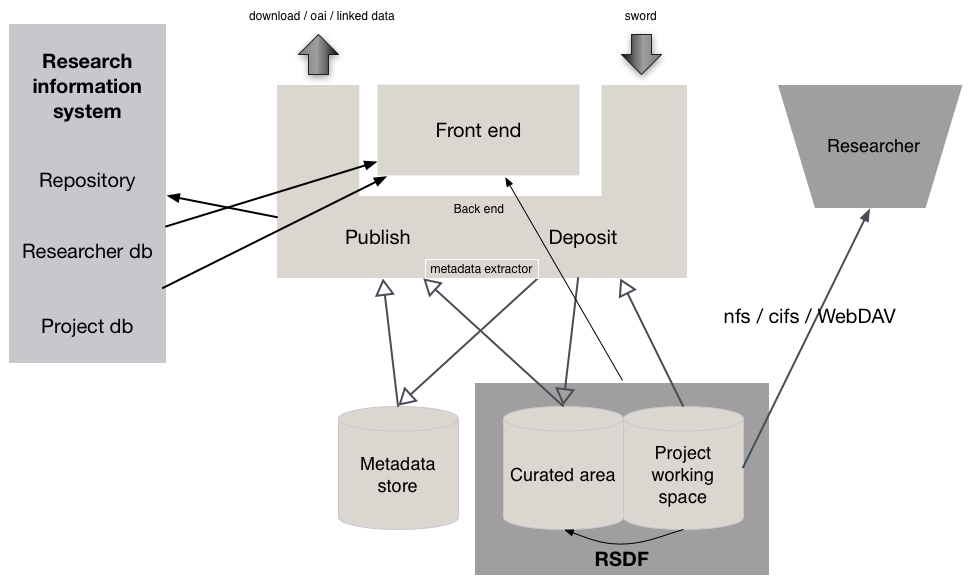
University of Bristol data.bris architecture
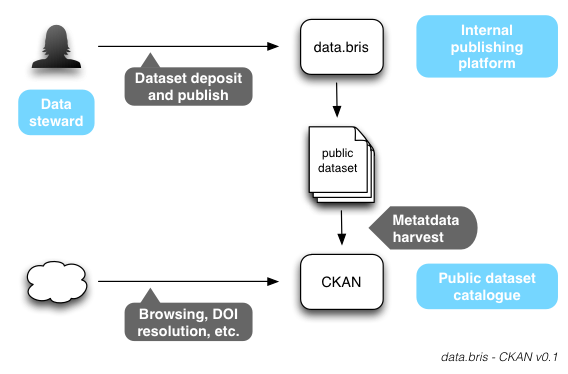
University of Bristol CKAN Portal Workflow
Project website Presentation link Institutional data portals and data sharing: systems are the easy bit.
Tom Parsons from the ADMIRe project described Nottingham as a research-intensive university with a large research income and emphasis on Medical & Health Sciences, Sciences, Engineering. Social Sciences and Arts disciplines. Their RDM policy commits to providing services for storage, backup, registration, deposit and preservation of research data. An extensive survey (and focus groups and interviews) inclusive of about 500 researchers was used to gather requirements.
The survey results showed the types of data created, with a large percentage of documents and spreadsheets (24% altogether). There was also a range of places where data is stored, with individual researchers choosing a variety of locations and methods. Overwhelmingly, little collection of metadata was reported. Sharing was quite restricted and in particularly limited to research groups and close colleagues. The resulting requirements also included institutional ones, such as being enterprise architecture compliant. The project felt that it was difficult to estimate the total amounts of research data, with 300TB being a rough estimate of a good amount to start with. Focus groups were used to categorise areas of concern (using methodology based on the California Digital Library model) – with metadata concerns resulting at the top and licensing and copyright being given low priority by respondents (suggested to be linked to the current low degree of sharing practice).
The project has now produced a diagram of architectural components required in their RDM system (public version published in this March 2013 report). This has been mapped to existing institutional systems and gaps have been identified. Next steps for the project included integrating the use of DMPonline and assignment of DOIs.


Project website Presentation: Creating a data repository and catalogue
Sally Rumsey spoke about the Univerity of Oxford's Databank data archive and DataFinder data catalogue. She described the journey of data from creation to discovery and dissemination as a data chain. Diagram slide. This chain can be considered as an idealised scenario, governed by policies and implemented in tested end-too-end services that fulfil the chain.

However the reality develops at a slightly slower pace. The project is currently engaged in writing a policy for assigning DOIs (and the institution has signed up to the BL DataCite service). Testing of the chain will be forthcoming once the systems are integrated. The services that are (to be) integrated comprise:
- Oxford DMPonline – being used to capture some of the metadata, which has been mapped to the storage metadata.
- DataStage - the conduit to bringing data into databank. It provides local data management, providing access controls (local or remote), metadata and deposit mechanisms to repositories, either subject-specific repositories or the institutional DataBank.
- Dataflow - provides an intuitive platform-agnostic interface to Datastage.
- DataBank - the digital repository created as an RDF Object Store, which comprises DOI assignment
- Datafinder - will provide a functioning catalogue based on a minimum core of metadata, including funder information (encompassing 2700 funders!) working with research systems; it is hoped that further metadata held across other systems can also be obtained.
Future plans include testing the data chain with users, working on plans for being able to scale storage to meet needs, working out a business model and providing supporting staff for the services, whilst continuing to enhance the features of service.
Joss Winn described how the Orbital project at University of Lincoln moved from a vision of an all-singing all-dancing RDM service to designing a more realistic joined-up service. The project moved from the aim of developing their own solution (around May 2012, described as a minimum viable product) to adopting CKAN – which provides 3 functions: access to a data store (held on a database), data file management, and a data repository managing access to data. The development of Orbital Bridge has bridged disparate institutional research systems into a coherent system.
By January 2013 the idea of a researcher dashboard, to co-ordinate a coherent approach to research information, spread across systems (such as awards management, staff profiles and reference management) came into being. This concept was presented to senior management, describing possible responsibilities across service departments. The project is feeding requirements for ICT provision of storage to address research data storage. One outcome from the project has been the formation of a team coming together and building up RDM expertise for the institution.
During the presentation a demo was shown of the researcher dashboard, which links to policies and training materials. The view onto research information include staff profile views, funded project views, and dataset views which link the information fed into the dashboard from CKAN. A public view onto the information about the data outputs is being developed alongside related information (e.g. publications and staff profiles). Check out this blog post on data deposit for several screenshots of the Researcher Dashboard in use and some videos in this earlier post.
Project website Presentation link
Graham Blyth and Tim Banks gave us a double-act as an update on the University of Leeds' RoaDMaP project plans on storage and archiving of research data. Graham explained that the project had not set out to build their own system but mainly to communicate with researchers and particularly investigate metadata needs. They have observed that storage needs can change e.g. new equipment can make storage requirements shoot up, and responding to earlier comments, Graham himself declared that he has developed a sceptical view about whether a statement on 'average' institutional storage requirements can be made. Metadata was then discussed under different headings: discover, reuse, repurpose, manage – some metadata needs are driven by third parties, for example archivists may be responsible for metadata in the longer term management (once the original creator is no longer around) or a re-purposer may contribute to the metadata when they come to the data from a different angle. There are still outstanding questions on the right level for defining objects as discovery objects e.g. collections or scans of the same object. There is still a gap for creating and managing metadata alongside data creation, particularly with data instruments (like CT scanners), which offer lots of potential for pre-filling metadata fields.
Tim Banks focused on lessons on storage particularly considering the need for longer term (20+ years) storage, immutability of stored objects, reasonable time from request to access, and the business models for longer term storage. Longer term challenges to be solved include unknowns in the volume of storage, rates of growth, choice of storage medium, integrity checks and ensuring security restrictions. He described scenarios for data requests varying from links of objects stored locally to data that requires request forms for data that is not immediately accessible. Further work is underway at the University of Leeds with Arkivum.com for pilot testing, where data is managed in their data centres. Typically costs for large volume storage for long periods has been worked out at £3.75 per Gb per 20 yrs (19p/GB/yr). An investigation into Escrow model (for finance and data) is also ongoing. Other providers of storage are also being considered.
Project website Presentation: Approaches to data repository and archive.