You are here
A macroscope for UK web history
A summary of the demo session presented by Andrew Jackson from the British Library at IDCC15 on their web archiving service with macroscope features.
In one of the demo sessions at IDCC15, Andrew Jackson from the British Library demonstrated a web archiving service that supports researchers interested in exploring history through the web. The service aims to offer different ways of searching and viewing results, trying to meet the needs of the information retrieval mental model of researchers. For example, historians are often interested in more than simply the top search result, and are looking to understand the context of the results returned by a search. The tool, which works as a historical search engine, extends searching beyond the URL (as in other services that retrieve a specific page to examine how it was in the past), by offering pharse searching, so that the historical context of the results of that phrase as a search term can be explored. Rather than interpreting results for the user (as popular search engines do by determining the most important result based on their own algorithms, and placing it first), the focus is on the user being allowed to slice and dice the search results for themselves.
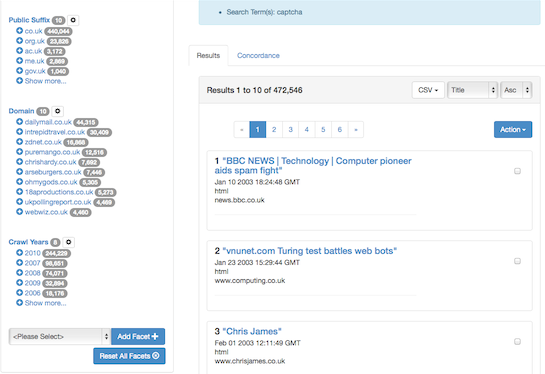
- A search for the term 'captcha', which returns two million results, shown by older first: the crawl years can be browsed and show development historically from results which discuss captcha as a technology to a later predominance of results which offer captcha services.
- Subsets of results can be examined, for example by extracting domains, examining linked sites, or the most linked. The links can reveal trends such as the growth of advertising and the use of social networking.
- Searches can be set to return results displayed by facets (such as by format, by domains), although these searches sift through two billion resources and can be quite slow to return.
- Graphs are used as a visualisation tool to reveal patterns. The term iPhone can be seen to rise and peak along the timeline in which the iPhone became available; compared to the results for the term Unix, the graph shows that the fraction of results returned for the latter search term grows smaller as the former rises.
- Results can be limited by public suffixes e.g. ac.uk Historical patterns can once again be discerned, as over the years the co.uk domain results dwarf those coming from the ac.uk domain, once the web moves from academic use to the mainstream.
- Although the trends allow some analysis of how topics have been dealt with historically on the web, what underlies the trend is not instantly made clear and requires some digging. Searching through the results for iPhone shows that the term was used before 2003, when it had been applied to some other phone set.
- Results for the term Genome show a peak in 2001, but looking at the underlying results reveals that the reason for this peak partly turns out to be a bug in the Sanger data base which generated several error reporting pages.
- Analysing the results for terrorist or terrorism over time shows not only the obvious peak in 2001, but also the baseline moving higher as time goes by.
The service was developed initially by funding through JISC and continues with funding from AHRC. One of the limits encountered in its development were due to scale: learning how to index the billions of resources that make up the service was a long process of learning. The technology is based on the solr software, utilising 30 TB of storage. The indexing and processing functions are separeted to spread the load. Some challenges for the future of the service were outlined: - how much more can be invested in the enhancing the usability of the service? - the value to researchers must be demonstrated to justify investment. - future sustainbility is a concern, since growth of pages is rapid at two billion additions per year, requiring a big investment and scaling up of efficiency for the service to keep pace with growth of the web in the future.