You are here
Report from RDAP 2014
The 5th annual Research Data Access and Preservation (RDAP) summit was held in San Diego, CA at the end of March. Having presented at the previous year’s event in Baltimore, MD, the DCC’s Martin Donnelly went along to catch up with recent data developments in the US, and to share with our North...
The 5th annual Research Data Access and Preservation (RDAP) summit was held in San Diego, CA at the end of March. Having presented at the previous year’s event in Baltimore, MD, the DCC’s Martin Donnelly went along to catch up with recent data developments in the US, and to share with our North American colleagues a few developments from this side of the Pond…

San Diego Marina
Day one’s opening keynote came from MacKenzie Smith, University Librarian at the University of California, Davis. MacKenzie used her talk to reiterate the purpose of academic librarians as facilitators of research: in British parlance, it is important that the tail does not start trying to wag the dog. Despite the increasing number of data mandates in the ecosystem – which she feels are gradually gaining public support, but suffer from being somewhat vague and seldom enforced – the compelling driver for getting better RDM performances out of researchers is its potential role in publications, promotions and tenure processes. Academics will go the extra mile when their activities contribute towards these goals, so support and training around data literacy are crucial.
MacKenzie’s talk was followed by a trio of panels, each of which featured three speakers addressing related topics, and each culminating with a shared question and answer session. First up was “Building a data management and curation program on a shoestring budget”, led by Steve Van Tuyl of Carnegie Mellon University. This panel featured Regina Raboin of Tufts University, Margaret Henderson from Virginia Commonwealth University, and Yasmeen Shorish, of James Madison University, also in Virginia. Regina introduced us to the NECDMC [pron. "nekdemik", URL: http://library.umassmed.edu/necdmc/index] curriculum for training and education of data librarians. Although concentrating on the STEM (Science, Technology, Engineering and Mathematics) subject areas, Regina suspected that some of the modules will be useable in other domains and disciplines. Yasmeen quickly stressed that her home institution is not a research-intensive university, and a show of hands revealed many delegates in similar positions. (With my UK hat on, I listened with interest and wondered how well Yasmeen’s content might translate to our own “research-aspirational” universities.) JMU’s librarians have been reacting to slightly frantic faculty help requests arising after the National Science Foundation’s somewhat vague DMP mandate, and have been grateful to receive help and good advice from colleagues at nearby University of Virginia, who have been instrumental in the development of the DMPTool consortium.
The next panel was on “Developing and implementing institutional policies on research data: ownership, preservation, and compliance” and was chaired by Stacy Konkiel from Indiana University and Aletia Morgan from Rutgers, and featured OCLC’s Ricky Erway who introduced OCLC’s strategy for embedding data management planning into existing ‘grant management’ workflows, Robert Downs from the Center for International Earth Science Information Network (CIESIN), who discussed the relationships between ISO 16363 requirements and adjacent policies e.g. Sustainability, Fiscal, Privacy, Linking, and Sara Mannheimer and Ayoung Yoon who spoke about the Dryad Digital Repository’s preservation policy, and specifically the issues arising around audit and certification via TRAC. They noted the current shortage of qualified potential auditors, as well as the costs that would be involved in carrying them out.
The final panel of the day was entitled “Collaboration and tension between institutions and units providing data management support” and was led by David Minor of the University of California, San Diego. Amanda Whitmire from Oregon State touched upon the age-old problem of engaging with long-serving faculty members while early-career researchers and graduate students are much more receptive to the data message, and they use enthusiastic (and willing) youngsters to trial new initiatives. Purdue’s Lisa Zilinski, spoke about the relationship between Libraries faculty, Centralized Library Services, Campus Services and actual Researchers, as well as the tools and methodologies used to support researchers and manage data, such as Data Curation Profiles, data literacy training, and the DMPTool. Finally, Stephanie Wright from the University of Washington how her role as “data concierge” had developed over the years.
Day one concluded with a group of lightning talks covering subjects ranging from community building, training and awareness-raising, workflows, metadata strategies and preserving computer games. The pick of the bunch came from Bill Mischo of the University of Illinois at Urbana-Champaign, who presented the beginning stages of an analysis and characterization exercise of 1260 National Science Foundation data management plans submitted by UIUC researchers. Bill left us on a bit of a cliff-hanger, as there’s a paper in preparation which will give the full results of the exercise, so that’s definitely one to look out for later on in the year.

Slide courtesy of William Mischo, University of Illinois (reproduced by kind permission)
Day two opened with another keynote, this time from Maryann Martone, Principal Investigator of the Neuroscience Information Framework (NIF), based locally at UCSD. Maryann started with what can sometimes be a controversial view, and often overlooked by researchers, namely that - despite the way the systems /silos are set up – there are no real boundaries between what data researchers from different disciplines may find useful; for example, “neuroscientists may be interested in fungal proteins to see what things stick to other things.” NIF provides “a semantic model for describing research resources… a new type of entity for new modes of scientific dissemination,” and a means to discover and search structured data. Resources are added manually and via automated text mining pipeline. Neuroscience is too broad for a controlled vocabulary, so metadata is entered via free text and then curated / federated.” Maryanne also tackled another data myth, that of neutrality: “there are no unbiased data sets,” she said – the act of depositing and uploading incorporates a wealth of assumptions, judgements and selections.
The first panel of the day dealt with training and education and was led by ICPSR’s Jared Lyle who picked up where Maryann left off. A well-prepared data collection, he said, contains information intended to be complete and self explanatory for future users, and that the process of curation should “do no harm” to the original data and metadata. Jared cited Limor Peer’s paper at the recent IDCC conference in San Francisco, which gives a number of persuasive reasons why researchers should take the time to ensure their data can be found and used by other researchers in the future. Emory’s Jen Doty gave us a case study of curating a particular research project via the ICPSR processing pipeline. This exercise underscored the importance of developing rapport/trust between data support services and Principal Investigators. Emory also recorded time spent on the tasks, and admitted that they could not currently afford to offer this level of curation for every project at the university; nonetheless, it was useful to be able to document the process and attach time/staffing requirements and costs to inform future plans. They will be calculating time requirements for future “tiered” service provision. At this point the chair interjected with an observation that “the perfect is the enemy of the good,” and that he himself felt he could spend a lifetime working on some data sets. From the floor, Yasmeen Shorish raised a concern that “time and money could be wasted on resources that never get reused.” This certainly is a risk, but a strong appraisal process backed with dashboard metrics can help to mitigate it. Duke’s Joel Herndon told a story around issues with decisions / annotations that made sense to the project team, but were incomprehensible to outsiders, asking “how do researchers know what’s obvious and what needs elucidation?” Finally, UCLA’s Libbie Stephenson gave an overview of a small, domain specific social science data archive, which has operated on a shoestring budget for almost fifty years.
The next panel gave the NSF DataNet projects an opportunity to bring the audience up to speed on progress. Dharma Akmon introduced SEAD, an active content repository aimed at the long-tail of data, or a “DropBox / Flickr for data” which also incorporates curation and preservation services. DataONE’s Amber Budden spoke about the stack of tools which underpin their service, TerraPop’s David Van Riper discussed integration and interoperability of disparate spatial data sets, and Mary Whitton, Project Manager with the DataNet Federation Consortium, covered the NSF’s current focus on production-ready, user-friendly software, and included an interesting slide listing what users (say they) want.
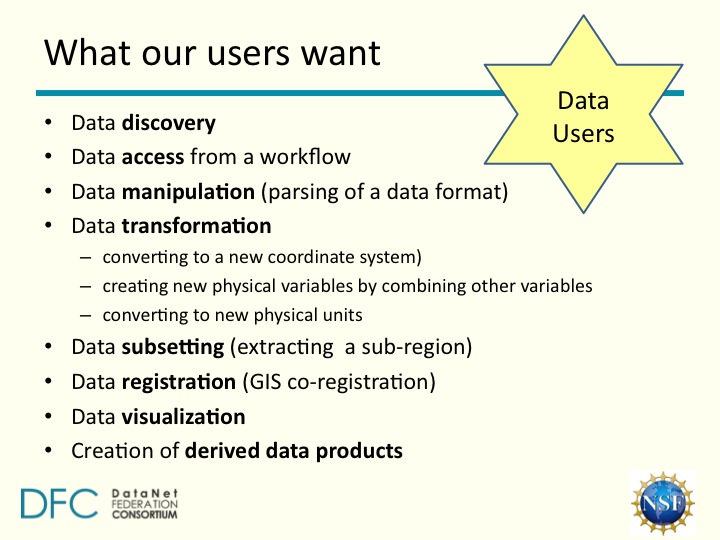 Slide courtesy of Mary Whitton, DataNet / Helen Tibbo, University of North Carolina at Chapel Hill (reproduced by kind permission)
Slide courtesy of Mary Whitton, DataNet / Helen Tibbo, University of North Carolina at Chapel Hill (reproduced by kind permission)
In the final panel of the summit, Cornell’s Wendy Kozlowski introduced three remotely-delivered presentations covering “Funding agency responses to federal requirements for public access to research results”. These were eagerly anticipated but delivered little concrete detail, so delegates were largely left to await future announcements from the US funders. From my point of view the most interesting titbit concerned the National Oceanic and Atmospheric Administration (NOAA), whose Grantee Data Sharing Policy is in the process of being ‘strengthened’. The detail is not yet finalised (“pre-decisional” was, I think, the term used), but tantalisingly the future policy may allow for data sharing costs to be included in project budgets, which has been less than clear-cut in the UK
And finally, to the poster session. We had lots of visitors at the DCC poster, mostly from the USA but also from Canada, Singapore and China; RDAP definitely seems to be becoming a more international event. Much gratitude was expressed for the DCC’s Creative Commons licenced resources, which have been used and reworked in North American universities. I thanked our friends for the positive feedback, and urged people to let us know when they found something useful so we can make our funders happy, and produce more resources in a similar vein.
P.S. The slides from many of the presentations and posters are available via Slideshare. (http://www.slideshare.net/search/slideshow?searchfrom=header&q=rdap14) If you want to check out a few different perspectives on this event, head over to Twitter and search the hashtag #rdap14