You are here
TMTOWTDI: Three data repository experiences in UK HE
Three data repository experiences at UK Higher Educational institutions: A report on parallel session 2B on data repositories and storage (group 1) at the JISC Managing Research Data Meeting in Nottingham, 24 October 2012. This session on data repositories and storage considered the repository...
Three data repository experiences at UK Higher Educational institutions: A report on parallel session 2B on data repositories and storage (group 1) at the JISC Managing Research Data Meeting in Nottingham, 24 October 2012.
This session on data repositories and storage considered the repository systems that support storing, depositing and exposing data at three universities. We heard from the University of Hull, the University of Hertfordshire and the University of Lincoln, where repository systems have been set up or extended through funded projects.
Three different solutions were described, each fitting a different approach taken by the institution. The examples illustrated the diversity of systems available and how they fit different needs. The presentations considered a variety of repository features that make them one of the cogs in the institutional research data management machinery. It is a while since I did any Perl programming, but the motto There's More Than One Way To Do It (TMTOWTDI) seemed to sum up this session pretty well.
Which repository platforms are they using?
The University of Hull is using the Hydra toolkit, which is a lightweight Ruby on Rails application that works with Fedora. Although Hydra is not a turn-key, out-of-the-box solution, it hides some of the complexities of Fedora, narrowing down some of the Fedora flexibility into a more focused toolkit to meet user's needs.
The University of Hertfordshire uses the dspace repository, a choice which predated the research data management activity. Their implementation, UHRA, was in production use, containing 8000 research outputs and interacting with their CRIS. Through a JISC project (RDTK) they have explored different routes of deposit: through a user interface, and using an API to submit data from desktop applications or datastage.
The University of Lincoln reported on the use of CKAN, software that is an open source project by the Open Knowledge Foundation, a project which has been running for six years. CKAN powers the data.gov.uk initiative, the EU commission data repository, and is used across different territories.
The history of adoption
Hull's selection of Fedora dates back to 2008 when discussions with other institutions sparked off ideas which developed into a community around Fedora, a community that the team at Hull can both tap into and feed into. The community effort was in response to Fedora being perceived as complex; since it is flexible, it can be hard to pin down which aspects of the flexibility to use when implementing it. Enabling simpler actions was the aim of Hydra, providing many points of access varied according to the content type (= the many heads of the hydra). Hydra Project Page
At Hertfordshire the thinking on using their existing dspace institutional repository for RDM was spurred on following a JISC MRD meeting in Leeds. A comment from Ben Ryan of the EPSRC, suggesting the vision that all data to support publications needs to be made available, inspired the Research Data Toolkit (RDTK) project to incorporate data deposit and use of the repository into the plan for this JISC project by adapting one of the work packages. In his presentation RDTK DataStage to DSpace, progress on a workflow for data deposit Bill Worthington described in particular the who, how and what of data deposit into their repository, considering different interfaces for deposit and metadata needs.
The evolution of CKAN from a catalogue tool to became a repository for data, hosting the data, and then offering a full API for data interaction (CRUD) including storage, led Lincoln to consider CKAN as a viable solution for their data repository during the Orbital project. There is a large growing community around CKAN reflecting growing interest to publish government data; however, outside of Lincoln, CKAN has not commonly been used for research data in Higher Education Institutions, so the University of Lincoln is pioneering in this respect. Discussions with some of the CKAN and Open Knowledge Foundation team were critical in shaping the decision at Lincoln; further reflections on their choices and notes on the decision-making process are available on the project blog.
How these solutions meet institutional needs
Chris Awre reported that for Hull, which he characterised as being a smaller institution, the choice was driven by five principles: The repository should be content agnostic, open standards based and scalable. "One thing we can guarantee is that there will be more content
"; It must understand relationships between content (not simply treat content as blobs) and must be managed within limited resource.
Further considerations included the assumptions that no repository solution can meet all the institution's needs, yet sustainable solutions require common infrastructure; the repository should not be a silo and should allow cross-fertilisation between content types; it would be easier to integrate one repository solution with the institution's other existing or future systems; no single institution can resource the development of a full range of solutions. Therefore the Hydra approach of distributed development by a community of partners, working towards different but shared Hydra heads (different points of access depending on the content), allowing for flexibility of content, met Hull's needs well. Hydra offered flexibility to use data sets.
Joss Winn, presenting for Lincoln, also recognised that "There is no single solution for every single use case
". One of the attractive features of CKAN is the ability to work with data, not just publish and catalogue it. In a blog post the detailed list of CKAN's suitability for RDM (as well as some limitations) are explored. Data visualisation and controlled access both make the list of requirements. Most of all despite the attractions of tools that do particular jobs and do them well, APIs to integrate with other institutional systems are essential. One other requirement set by Orbital was to provide direct access to the raw data, rather than data in a form that has to be mediated or transformed.
dspace was already embedded at University of Hertfordshire. The routes of data deposit and the implications for workflows were considered by the RDTK project. When using the user interface route offered by dspace, the burden of metadata record completion falls to the submitter at the point of deposit (usually the principal investigator or PI). Exploring deposit using SWORD as an interface opened up other options for managing the workflow that may better suit institutional plans, such as sharing the task of metadata entry or validation with other roles in the institution e.g. repository administrators or curators. The SWORD interface offers a method of integration with desktop applications or datastage – around which alternative deposit tools or workflows can be offered for these other roles.
More about the repository systems
Hydra was characterised as: a repository solution, a community, a technical framework, open source software. It is based on CRUD – create, read, update, delete – operations, and contains a system of template-based interfaces to manage human interactions. Hydra allows you to write whatever templates you need, offering flexibility for content types. One example that has been developed offers login/role based template selections.
Orbital gave presentations on their use of CKAN in two sessions of the meeting, and supplementary information on CKAN is available from the sister presentation, An API first approach to integrating CKAN with RDM services as well as the project blog posts.
For some further information on integrating datastage with dspace, check the links in one of the next sections.
Examples of use
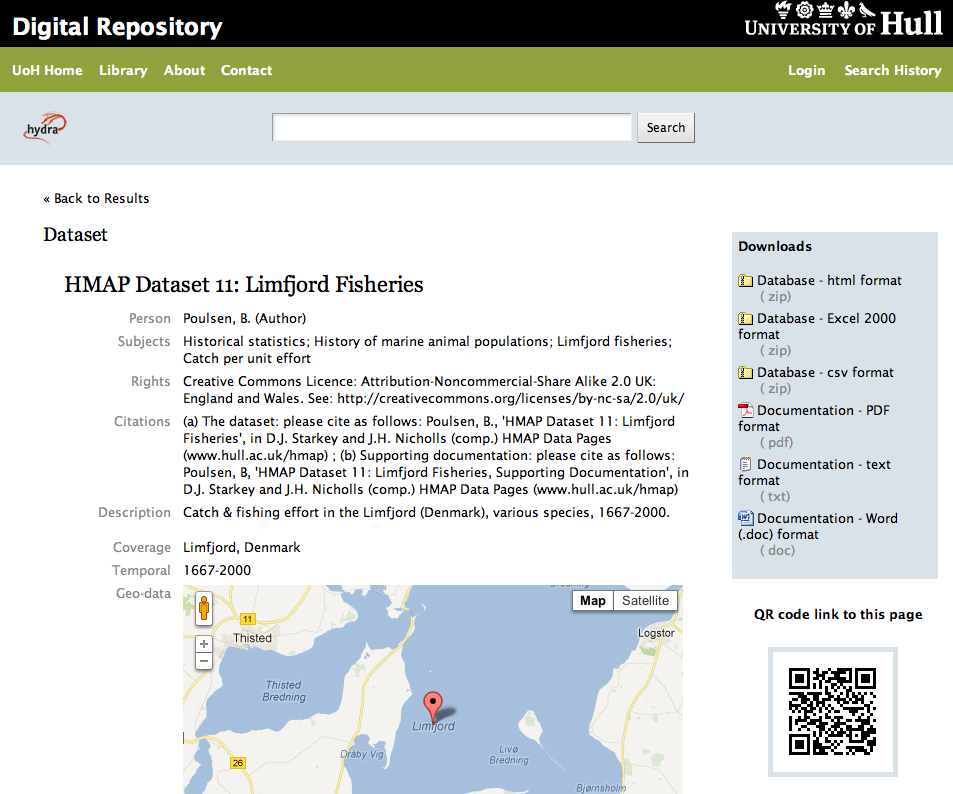
The presentation on the Hydra implementation at Hull showed examples of entries for both journals and datasets, demonstrating how different metadata and features can be displayed according to content type. Content can be ordered structurally or through display sets, creating on-the-fly collections. The following is a screen shot for a dataset entry, showing visualisation features:
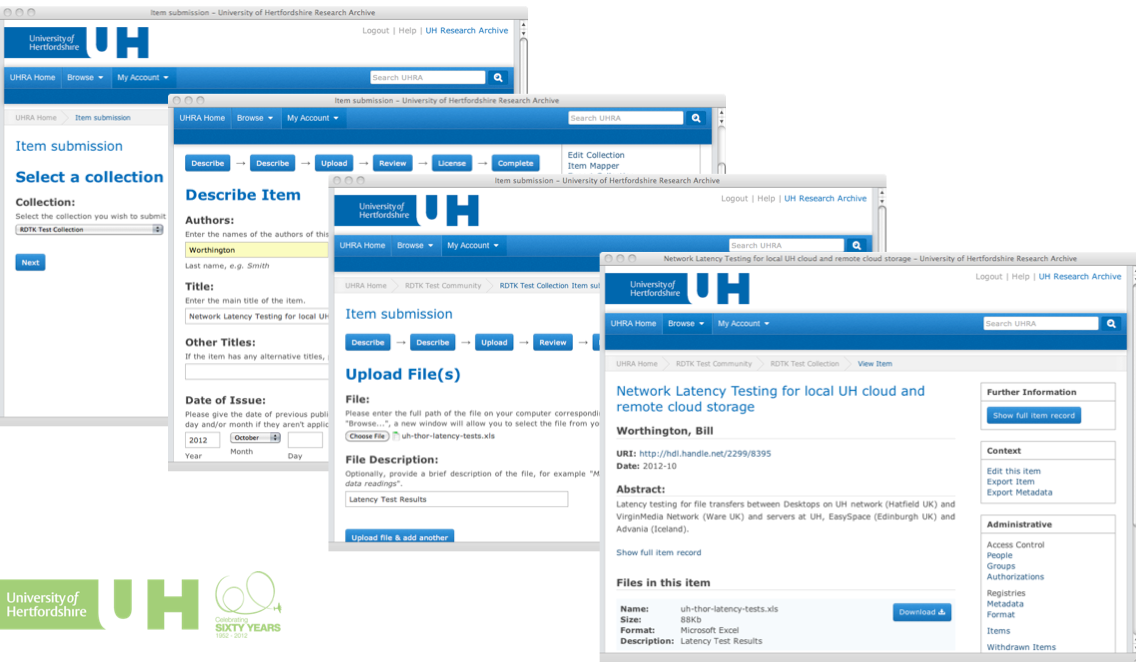
The University of Hertfordshire showed the data deposit workflows that have been implemented, considering questions that can be asked around the process, such as who has the responsibility for metadata entry. The How of metadata entry is related to the Who question: the user interface method in dspace requires lots of input when used by the PI for first submission, requiring a record to be completed at that stage. When SWORD methods are used, the record can be first entered with a minimal metadata and then completed by a mediator (e.g. a librarian). The experience of the university with other outputs was that the deposit and metadata entry process is very mediated, with administrators taking on the role of completingthe required metadata. Exploring alternative routes of deposit (HOW) has opened up options for considering the WHO. The screens below capture some of the deposit workflows as they are being implemented at Hertfordshire.
Lincoln reported on a specific Case Study involving the Lincoln Centre for Autonomous Systems. The team implementing CKAN at Lincoln worked closely with the researchers to meet their need for sharing data to support collaborations with external groups.
Metadata considerations
The Hull schema is currently based on MODS which suited the marine data, but they recognise that the schema might have to be simplified for generic datasets.
In deciding about metadata, Hertfordshire is being informed by the data itself, taking into account standards (such as Dublin Core) and also consider accommodating local and third party hosted solutions, as well as being informed by other JISC MRD work (such as that at Essex). There is also a need to think of catalogue functionality.
Extent of implementation
The Hydra implementation at Hull is currently used for both faculty and students, and to manage internal and external content. Faculty are using it to manage research outputs, both for dissemination and to manage data. The Hull Hydra team have worked in particular with one group of researchers in the history department, which has informed the institutional work on datasets through the History DMP project. The data set display demonstrated in the example above is based on that project. Student content includes dissertations, exam papers and student handbooks. Work on integrating Hydra at Hull has also simplified roles and access control, which is tied to the institutional CAS system, allowing access levels (e.g. internal, open, restricted to groups).
While working on secure access to data, Orbital have uploaded course data and organisational structures to CKAN. This data can be queried. They report using the DataStore API with ElasticSearch (subject to future changes).
At Hertfordshire the UHRA has seen improvements in upgrading to a new version of dspace, improving ETHOS interoperability, extending storage, offering a new theme for the institution, improved searching and discoverability. The deposit processes have been expanded as described earlier. The manual deposit workflow includes two description sections, a license section, and assignment to a collection. Deposit has proven to be quite straightforward to implement and works for small data. The choice for who carries out the deposit is still being debated; as mentioned administrators are being considered. The use of PI involvement is seen as a potential method to raise RDM awareness. There is also a user interface to modify metadata schemas.
The projects' experiences of these repository systems and their interactions with other projects
The distributed partners in Hydra reported that they found it easy to learn. Hydra was described as a maturing solution which is work in progress.
The team at Hertfordshire feel that the large community of users of dspace is a benefit. Their description of the dspace deposit app which they have used to develop the deposit options was 'clunky but effective' – they worked with an external developer to get this application working for UHRA. Hertfordshire have also done work on integrating Datastage, which so far is installed on a virtual machine, and could be rolled out as units, to groups that require collaborative storage. However some aspects are not fully working yet, such as submitting data as a package. Work on a solution is ongoing. Other hiccups which have been encountered relate to the harvesting of EU-funded data by OpenAire which was reported as not working yet on the day of the meeting; some of the outputs come out of CRIS which needs to support the metadata before it can be imported into dspace.
Following this Nottingham meeting, information was supplied on the JISC-MRD mailing list, with pointers to other work on integrating datatage with dspace, a wiki entry and a blog post by C4DM.
Whilst Orbital are generally happy with CKAN, having had success in storing data and have got some areas to work well, they do report occasional problems arising from the development history of CKAN and consider their system to be a beta implementation e.g. “some areas of CKAN do feel like they’re a collection of hacks built on top of some more hacks built on a framework which is built on another framework which is built on a collection of libraries which is built on a hack.” However they report on a positive experience of the CKAN community, with a very active developer mailing list, user mailing list, github sites and irc channels all being available. They have identified at least one limitation of CKAN, which is how it deals with the concept of research groups and organisations, and they have currently used group labels to create collections. Fixing this seems to be on the development roadmap for CKAN, with a new CKAN version due at the end of the year which should support organisations.
Future plans and next steps
The wider Hydra community, including institutions in the US, has some members looking at how to use the Hydra toolkit over alternative repositories. There is also interest in gaining more experience of small science data and big data. At Hull specifically, Hydra has been embedded at the core of the EPSRC roadmap. Future plans include:
- Exploring work with Datacite on assigning identifiers – comparing these to the persistent identifiers that are available through Fedora, and considering whether DataCite identifiers confer authority.
- Training staff in the the history department to deposit their datasets.
- Exploring what it means to be a data catalogue
- Working with the IT service, who are implementing a storage solution, looking at options which may include using some cloud services, local storage and potentially offering a mixed environment.
- Exploring connections to external repositories, with the institutional repository perhaps holding a record stub to point to an external repository
- Formation of a cross-faculty working group at institutional level, to implement the roadmap and consider future repository needs.
- Expand their collection of use cases, moving on the focus from history to other departments: conversations are going on with Music and English.
At Hertfordshire the immediate plans include showing academics that different types of data can be hosted if Tier 1 or 2 repositories are not available, and they are hoping to demonstrate improved citation. Getting datastage to work is another aim, to give researchers an option of collaboration beyond the institution and an inbuilt workflow.
Thier next steps are described as:
- evangelise with case studies: using spreadsheets from social-economic data, audiovisual data for oral histories, tabular data from astronomers (currently published on their own website), matlab scripts from atmospheric instrument development – with a focus on adding data that supports publications.
- explore an ingest model similar to the one used for other outputs, where an administrator follows up the researcher to fill in gaps in metadata; this would have central resource implications.
- consider choice of identifier solutions together with the wider community
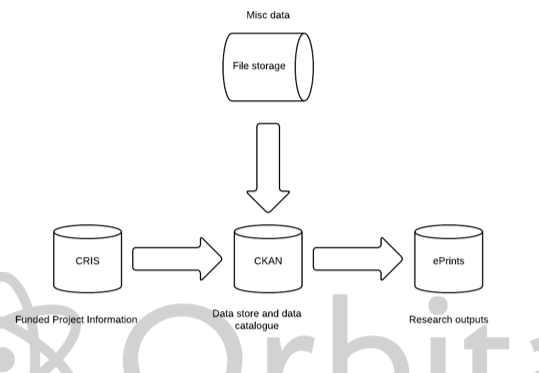
The future work at Lincoln concentrates on the 'Orbital bridge' a central point for RDM activity. The Bridge connects CKAN to other critical institutional systems such as their eprints instance (containing publications), an awards management system, and file storage. The bridge to eprints is being written using SWORD. A business case needs to be made for integrating CKAN with local storage. Lincoln have not yet donated back a plugin for CKAN since most of their work is about bridging, however feeding changes back into CKAN would be considered.
Further information and support.
Presentation on Hydra from JISC MRD Nottingham meeting: Using Hydra's flexibility to manage datasets
Hydra UK held an event on “Flexible repository solutions to meet varied needs” on Thursday 22nd November 2012, 11:00am – 4:00pm at the LSE Library, London. Links for the materials will be added as soon as available. There is also a Hydra github site for downloads.
The University of Hertfordshire's poster and three presentations are available from the RDTK project blog, together with some reflections about the event; the presentation on data deposit into dspace is at: http://research-data-toolkit.herts.ac.uk/document/rdtk-dataset-deposit-presentation-jiscmrd-progress-workshop-nottingham-2012/
Orbital has a blog post linking to both presentations given at the meeting, and two other blog posts http://orbital.blogs.lincoln.ac.uk/2012/10/24/presentations-from-the-jisc-mrd-programme-progress-meeting/ They recommend demo.ckan.org to showcase the upcoming CKAN v2
Suggested areas of work across the JISCMRD community
In addition to the focus on the specific systems in use at the three institutions, this session included suggestions and discussions on some common interests that could be supported through JISC Managing Research Data activity, coming both from the presenters and the participants in the break out group:
- How can JISC MRD/DCC support community initiatives like Hydra and CKAN?
- There is a need for conversations around which data is held institutionally and about interactions with external repositories.
- There are questions around the use of identifiers (such as DOIs). Do DOIs give gravitas, is this sufficient reason to prefer them as form of digital identifier? What are the implications of using DOIs from different services for different data types? How strictly do identifier service providers monitor and enforce the types of digital objects to which the identifier is assigned? What processes are available for minting DOIs, including directly through the British Library DataCite service? Is there a possible role for an HEI 'consortium' model? Prior to the Nottingham meeting a workshop on digital identifiers for datasets had been proposed on the JISCMRD list, and this topic received great interest with a lively discussion from list subscribers.
- At what granularity should metadata be assigned? What are the implications of implementing collection-level metadata rather than file-level metadata?
Note: The information provided in the slides and during the presentation by Orbital has been supplemented by comments provided in the blog links in the slides. Thanks are given to the authors of the presentations for re-use of their images.